- Introduction
- Getting Started
- Getting InfluxDB and Grafana running in Docker
- Future things I want to do
Introduction
I just want to start off by saying, this is the first TIG stack deployment I have ever done, and was a lot easier then I expected (at least for this use case). I also have another use case of wanting to monitor logs to determine how often issues are appearing, and that use case could be a bit more challenging, however I have not done a lot of research into it.
I have a homemade NAS system at home, that incorporates ESXi, Ubuntu, ZFS, and Docker for applications/services I want to run. One of the biggest issues I have is monitoring long term performance on the device. Because I am not running VSphere and am solely running ESXi, it makes it difficult to grab metrics from the hypervisor, so I am left to grab metrics from the guest.
I wanted a way to have historical data from the system in case something went horribly (not really, but maybe) wrong for troubleshooting purposes, being sent to another server.
A bit of background on the system in place here, and yes - I am a data hoarder and a fan of data storage systems.
TIG System Specs:
- CPU: Intel NUC 8i3BEH1
- Memory: 16GB RAM
- Storage: 1x 128 GB NVME
ESXi Hypervisor Specs:
- OS: ESXi 7.0
- CPU: AMD Ryzen 7 1700 Eight-Core Processor
- Memory: 64 GB ECC Memory
- Storage:
- NVME: 1x Samsung 970 Pro 1TB, 1x WD SN750 1TB
- SSD: 2x Intel DC S3510 120 GB
- SATA: 6x WD Red 6TB Drives
- GPU: Nvidia GT 710
- Motherboard: ASRock X470 Master SLI/AC
- HBA: LSI 2008 PCI-E Card
NAS Guest Specs:
- OS: Ubuntu 20.04 LTS
- Memory: 48 GB
- Root Drive: 40 GB
- Passthrough:
- HBA: LSI SAS2008 PCI-Express Fusion-MPT SAS-2 Falcon rev. 03 (Flashed to IT mode)
- ZFS Pool: 32 TB (WD RED 6TB Drives - SATA_WDC_WD60EFRX-68L_WD)
- Cache: 1TB
You might think 48 GB of memory is overkill for a system that mainly deals with storage and a few applications. Unfortunately, not at the current moment - but I do agree, it is overkill. I also use rclone as an online storage system with Google Drive as a backend. Meaning this is my normal:
|
|
There is definitely some room for improvement, don’t get me wrong, but at the moment. However, without any historical data to go off of and just looking at the above command fro time to time, it isn’t sufficient to fine tune it further and make optimizations.
So with all that said and done, the things I wanted to monitor came out to be:
- Memory Usage
- CPU Usage
- File System Usage
- Docker
- ZFS Pool
- Network Traffic
Getting Started
Getting InfluxDB and Grafana running in Docker
Thankfully, Grafana and InfluxDB already provide decent out of the box docker images, so no modification is needed for a small scale deployment and what I am trying to accomplish.
I started out doing this for my docker-compose file
|
|
I am aware Docker volume stores are supposedly the more supported/official way to go, due to their flexibility and ease of use, and honestly I do agree with that for larger scale systems. For my use case, it’s just more convenient to me to use bind mounts at the current moment.
You might notice I don’t have a web front end (something like Nginx, Traefik) in use here. I am hosting this for internal use only and it is not publicly available. Any public facing service goes through a different endpoint entirely (an nginx entrypoint). If I was setting up TIG publicly, I would consider using Traefik and enable docker swarm for ease of use. This is something I might do in the future, as I would love to implement Google’s oAuth service into Grafana, and at that point, I would feel more comfortable putting the service publicly on the internet for me to auth into.
Anyways, getting back on track.
Configuring Telegraf
Setting up telegraf is super easy, install the application, uncomment out the lines you want to monitor, and potentially add other information to.
On your system that you want to monitor (in my case, the NAS), edit /etc/telegraf/telegraf.conf with your favorite editor. An example of my configuration file is below.
|
|
I won’t lie, I might have gone a bit overboard on the configuration of monitoring details, especially for what my original intent was to log. However, this achieves what I want. With this, I get a pretty decent reporting tool. Some improvements above could be using variables in the configuration file, to allow for the file to be replicated or used without having to modify or specialize it to specific systems. This is something I am planning on doing as I write up my ansible repo.
Configuring InfluxDB
Considering this TIG is only monitoring a single host, I setup InfluxDB to have a longer retention time of the data, specifically two years worth of time. If it was monitoring several systems, I would probably lower this to 6 months for 5 devices, mainly just to be on the conservative side.
|
|
Once you have changed retention, and have telegraf running, double check that you have data feeding in correctly by checking one of the values, an example of that can be done by performing the following command:
|
|
From here, you should be able to start setting up graphs in Grafana.
Configuring Graphs in Grafana
Grafana hosts a lot of good template graphfs here, and admittedly, a lot of them for my use case don’t work (beacuse I was not using Docker Swarm, or the default template just didn’t align with my database). So it required a bit of rework in some cases to fix the Variables configurations.
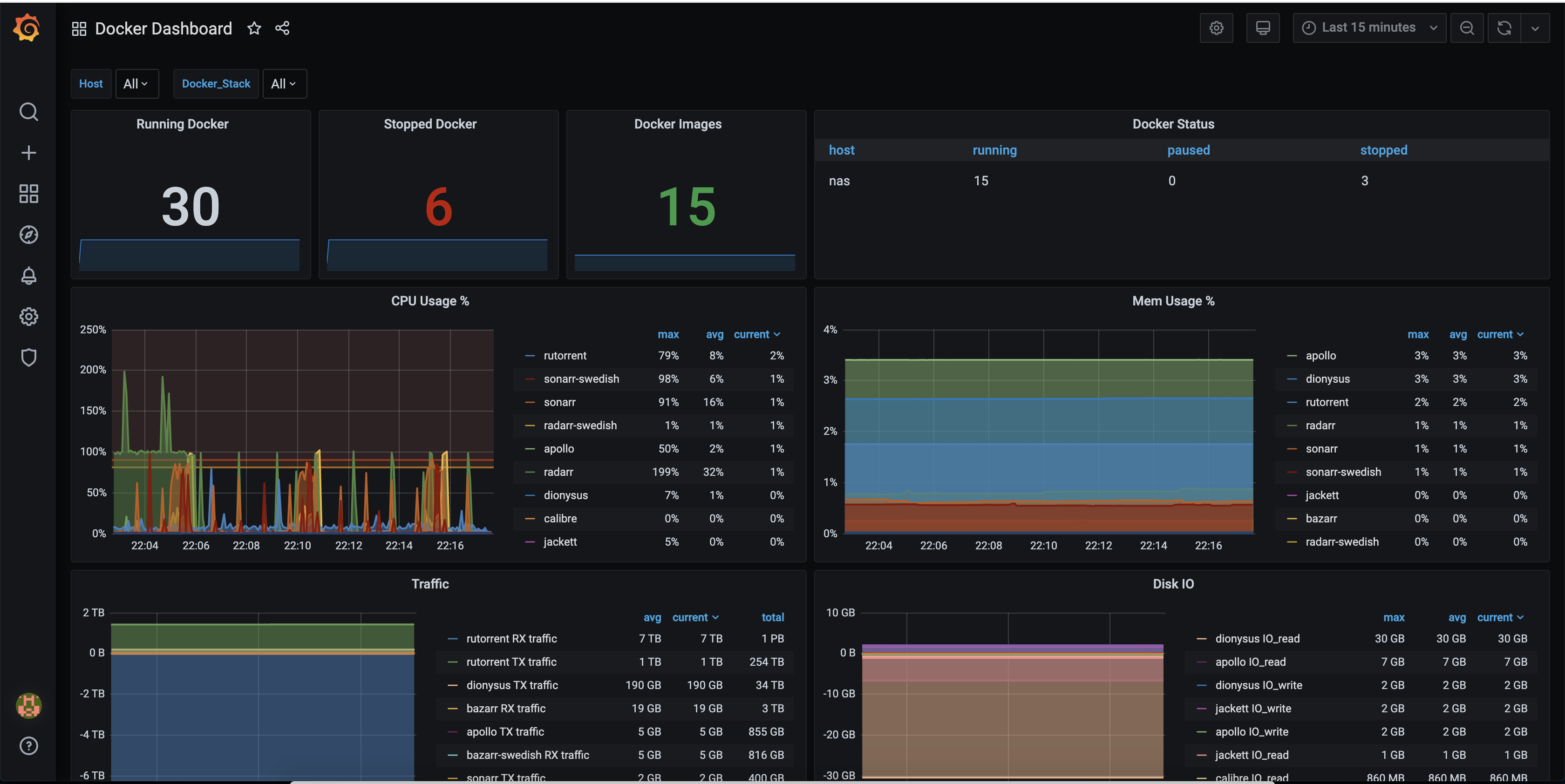
When it comes to System Performance, I came across another pre-made graph, that had the features I wanted, but, didn’t work instantly when loading via the dashboard id. After a bit of tweaking to data sources, and Variables, I eventually got it working well and now have a rotating dashboard.
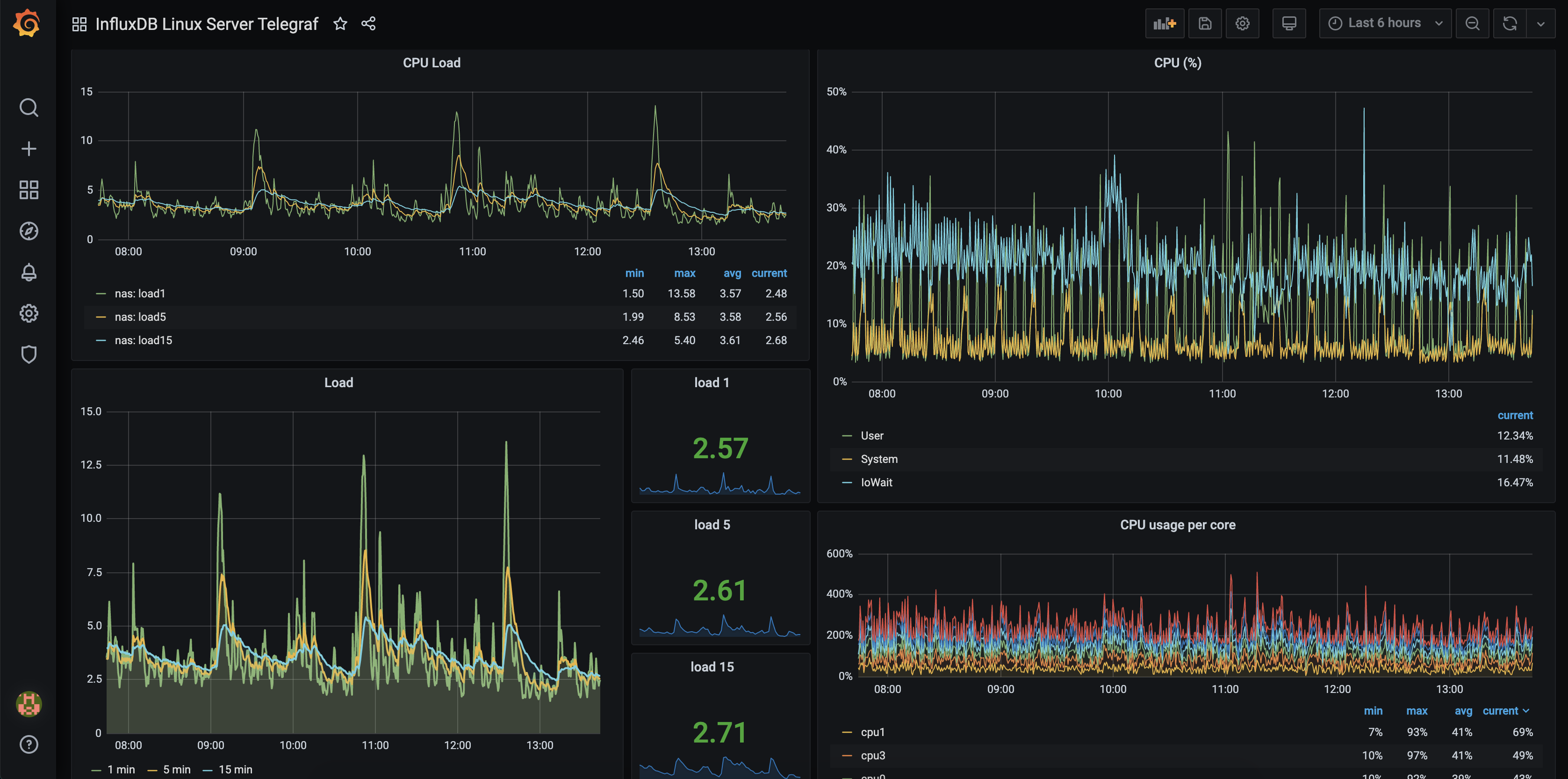
Future things I want to do
I really want to look into using Grafana Infinity to pull public data, and have some ideas on using some of the other public plugins. As I mentioned, I really want to pull in logs from different systems as datasources, namely rclone, nginx/traefik, pihole, and unifi to name a few.
I had done some research into scraping smart fans, and using temperature sensors as input data, but, living in a 400sqft apartment there is not a lot of variation, and unfortunately, I don’t have a lot of electrical outlets in my apartment. My entire bedroom has two.
However, this was a pretty good learning experience, and a good start going forward. Plenty of room to expand as I get more space and more time to utilize it.
I also reached out to some of my co-workers to see if they could tell me what the newest and best thing is, and have been hearing a lot about netdata.cloud, so that is also something I may look at moving to in the long term.